
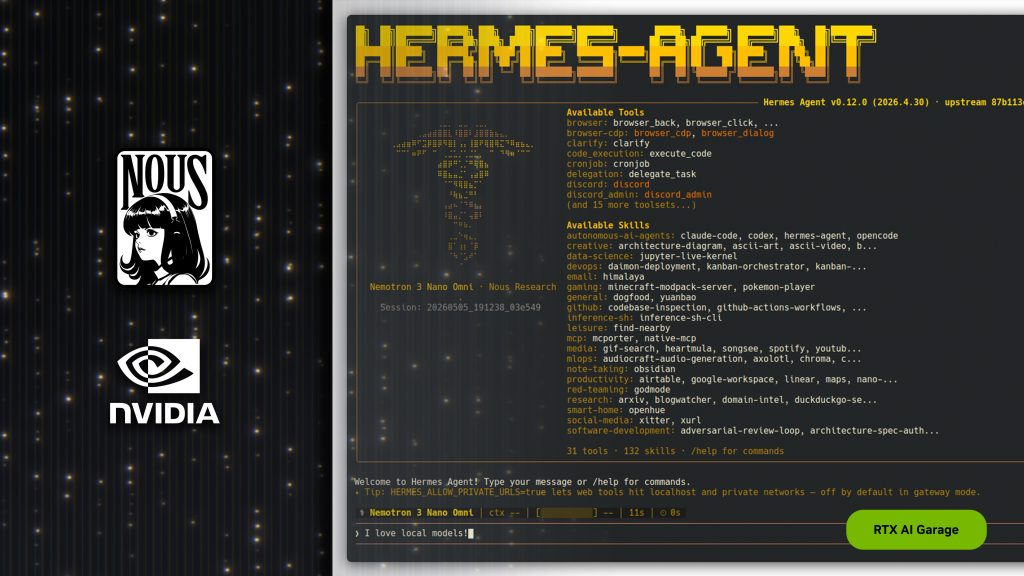
NVIDIA porta sotto i riflettori Hermes Agent, framework open source pensato per agenti AI locali e sempre attivi: il progetto punta su affidabilità, auto-miglioramento e uso con modelli come Qwen 3.6. La piattaforma è ottimizzata per PC RTX, workstation RTX PRO e DGX Spark. L’idea è far girare agenti personali più rapidi e autonomi direttamente sull’hardware dell’utente. Per developer e appassionati AI, il tema è sempre più pratico: meno cloud obbligatorio, più AI locale.
NVIDIA Hermes entra nella nuova fase degli agenti AI locali, quella in cui il computer non esegue solo un comando alla volta, ma può pianificare, adattarsi e migliorare nel tempo. Il progetto nasce da Nous Research e viene raccontato da NVIDIA come una delle novità più interessanti del mondo RTX AI Garage.
Il punto di partenza è semplice: gli agenti AI stanno cambiando il modo in cui molte persone lavorano con software, file, messaggi e automazioni. Però, per funzionare bene, devono essere affidabili, rapidi e capaci di mantenere una certa continuità nel tempo.
Hermes prova a rispondere proprio a queste esigenze: non è legato a un solo provider o a un solo modello, può girare localmente e si adatta bene a sistemi come NVIDIA RTX PC, RTX PRO workstation e NVIDIA DGX Spark.
NVIDIA Hermes e agenti che imparano nel tempo
La funzione più interessante di Hermes Agent riguarda le cosiddette Self-Evolving Skills. In pratica, quando l’agente affronta un compito complesso o riceve feedback, può salvare ciò che ha imparato sotto forma di nuova abilità.
Questo permette al sistema di migliorare progressivamente. Non parliamo di una semplice chat che dimentica tutto alla sessione successiva, ma di un agente che costruisce un piccolo patrimonio operativo.
Hermes usa anche sub-agenti isolati, cioè lavoratori temporanei dedicati a singole attività: questa struttura aiuta a mantenere più ordinato il contesto, riduce la confusione e permette di lavorare meglio anche con finestre di contesto più piccole.
Per l’AI locale è un passaggio utile: i modelli eseguiti su PC devono gestire bene memoria, risorse e priorità, senza sprecare calcolo.
Perché NVIDIA Hermes punta sull’AI locale
NVIDIA ha insistito molto sul concetto di esecuzione locale: se agente e modello linguistico girano sul dispositivo dell’utente, la qualità dell’esperienza dipende in modo diretto dall’hardware.
Qui entrano in gioco le GPU RTX, i Tensor Core e le workstation RTX PRO. L’obiettivo è ridurre latenza, aumentare throughput e rendere più veloci attività multi-step, generazione di strumenti, analisi di file e automazioni.
Per un utente evoluto, questo significa poter usare agenti AI senza dipendere sempre dal cloud, per uno sviluppatore, invece, significa testare workflow locali, integrare strumenti personali e creare automazioni più controllabili.
Naturalmente, il cloud resta importante per molti scenari, però l’AI locale sta diventando una strada più credibile, soprattutto quando i modelli diventano più efficienti.
Qwen 3.6 lavora con PC RTX e DGX Spark
NVIDIA ha citato anche i nuovi modelli Qwen 3.6 di Alibaba, pensati per offrire prestazioni elevate con pesi open weight. Il modello Qwen 3.6 35B gira con circa 20 GB di memoria, pur superando modelli precedenti molto più grandi.
Secondo NVIDIA, Qwen 3.6 27B riesce a eguagliare l’accuratezza di modelli da centinaia di miliardi di parametri, restando molto più compatto. Questo aspetto è importante perché rende più realistica l’esecuzione locale su macchine potenti, ma non necessariamente da data center.
Su GPU RTX di fascia alta, questi modelli possono offrire una risposta più rapida per agenti come Hermes. Il risultato è un agente che può lavorare su più passaggi senza tempi morti troppo lunghi.
NVIDIA Hermes su DGX Spark
NVIDIA DGX Spark viene presentato come una macchina compatta per agenti sempre attivi: ha 128 GB di memoria unificata e offre 1 petaflop di prestazioni AI, con l’obiettivo di sostenere workflow agentici continui durante la giornata.
È un prodotto pensato per chi vuole eseguire modelli importanti in locale, senza affidare tutto a server remoti. NVIDIA ha spiegato che DGX Spark può gestire modelli mixture-of-experts da 120 miliardi di parametri per sessioni prolungate.
Con Qwen 3.6 35B, però, si può ottenere un livello di intelligenza simile con un’impronta più leggera. Questo libera risorse per carichi concorrenti, test, strumenti agentici e attività parallele.
Per chi lavora su agenti autonomi, DGX Spark diventa quindi una piattaforma dedicata, più vicina a un laboratorio AI personale che a un PC tradizionale.
Come iniziare con Hermes Agent
NVIDIA ha indicato un percorso abbastanza diretto per provare Hermes Agent: si parte dal repository GitHub del progetto, poi si abbina l’agente a un modello locale e a un runtime compatibile.
Le opzioni citate includono llama.cpp, LM Studio e Ollama. Hermes include già supporto per LM Studio e Ollama, quindi l’avvio risulta più accessibile per chi ha già confidenza con modelli locali.
Questo rende il progetto interessante non solo per ricercatori e developer, ma anche per utenti esperti che vogliono costruire agenti personali, automazioni di lavoro o assistenti locali sempre disponibili.
Il vantaggio sta nella combinazione tra framework, modello e hardware. Hermes organizza il lavoro, Qwen 3.6 offre la parte linguistica e le GPU NVIDIA accelerano inferenza e operazioni agentiche.
Agenti AI sempre più vicini al PC personale
La direzione di NVIDIA è abbastanza netta: gli agenti AI non resteranno solo servizi remoti dentro browser o app cloud. Una parte crescente di questi strumenti girerà direttamente su PC, workstation e macchine compatte dedicate.
NVIDIA Hermes racconta questa evoluzione da un punto di vista pratico. Non basta avere un modello potente, serve un framework capace di orchestrare compiti, creare abilità, usare strumenti e migliorare nel tempo.
Per creator, sviluppatori e utenti avanzati, l’AI locale può diventare una risorsa di lavoro quotidiana. Non sostituisce il cloud, ma lo affianca con più controllo, più continuità e una migliore gestione dei dati sul proprio hardware.
La sfida ora passa dall’esperimento alla routine: se agenti come Hermes saranno abbastanza semplici da installare, stabili nell’uso e rapidi su hardware RTX, l’AI agentica locale potrà uscire dalla nicchia e diventare una parte reale del computer personale.
Articoli che potrebbero interessarti


